構造化データ
序章
ウェブページを読むとき、私たちは「非構造化」されたコンテンツを消費しています。段落を読み、メディアを検証し、消化したものを検討する。このプロセスの一環として、私たちは直感と文脈(主題に精通しているなど)を適用して、重要なテーマ、データポイント、エンティティ、および関係を特定します。私たち人間は、この作業を非常に得意としています。
しかし、このような直感や文脈は、ソフトウェアで再現することが困難です。システムが高い信頼性を持って解析し、重要なテーマを特定し、抽出することは難しいのです。
このような制限は、私たちが効果的に構築・創造できるものの種類を制限し、ウェブテクノロジーの「スマートさ」を制限することになります。
情報に構造を導入することで、ソフトウェアがコンテンツを理解するのをはるかに容易_にできます。このためには、ラベルやメタデータを追加して、主要な概念や実体、およびそれらの特性や関係を特定します。
機械が構造化されたデータを確実に、かつ大規模に抽出することができれば、よりスマートな新しいタイプのソフトウェア、システム、サービス、ビジネスが可能になります。
Web Almanacの「構造化データ」の章の目的は、構造化データが現在ウェブ上でどのように使用されているかを探ることです。これにより、現在の状況、課題、および機会についての洞察が得られることを期待しています。
この章は『Web Almanac』にはじめて掲載されたため、残念ながら比較のための過去データが不足しています。今後の章では、対前年比の傾向も探っていく予定です。
主要コンセプト
構造化データは、複雑な風景であり、本質的に抽象的で「メタ」なものである。構造化データの重要性と潜在的な影響を理解するために、以下の主要な概念を調べてみる価値があります。
セマンティックウェブ
公開されたウェブページに構造化データを追加し、それらのページが含む(あるいはそれに関する、あるいは参照する)エンティティを定義すると、リンクデータの形式ができ上がります。
私たちは、コンテンツに含まれる(あるいは関連する)事柄について、3つの組みという形で供述を行います。この 記事 はこの 人 によって 承認 された」、「その 動画 は 猫 に ついて だ」というような記述です。
このようにコンテンツを記述することで、機械がウェブページやウェブサイトをデータベースとして扱うことができるようになります。規模が大きくなれば、セマンティックウェブ、すなわち巨大なグローバル情報データベースを構築できます。
セマンティックウェブとは、ウェブ上のデータを、表示目的だけでなく、自動化、統合、様々なアプリケーション間でのデータの再利用ができるように定義・リンクするという考えを実現するために、W3Cが始めた長期プロジェクトの名称です。
それは、ビジネス、テクノロジー、そして社会に豊かな可能性をもたらします。
検索エンジン、そしてその先へ
現在、構造化データのもっとも広範な消費者は、サーチエンジンとソーシャル・メディア・プラットフォームである。
ほとんどの主要な検索エンジンでは、ウェブサイトの所有者は、さまざまな種類の構造化データをウェブサイトに実装することによって、さまざまな形式の 豊富な結果(可視性とトラフィックに影響を与える可能性があります)の資格を得ることができます。
実際、検索エンジンは、構造化データの一般的な採用(および 教育周り)において、ウェブ全体で非常に大きな役割を担っています。この章は、Web Almanac 去年のSEOの章から生まれたということです。近年では、検索エンジンの影響もあり、schema.orgが構造化データの選択語彙として普及しました。
さらに、ソーシャルメディアプラットフォームは、コンテンツがプラットフォーム上で共有(またはリンク)されたときに、コンテンツの読み方や表示方法に影響を与えるため構造化データに依存しています。これらのプラットフォームにおけるリッチなプレビュー、カスタマイズされたタイトルと説明文、およびインタラクティブ性は、多くの場合、構造化データによって実現されています。
しかし、ここで見て理解すべきことは、検索エンジンの最適化やソーシャルメディアのメリットだけではありません。構造化データの規模、多様性、影響、そして可能性はリッチリザルト、検索エンジンをはるかに超え、schema.orgをはるかに超えるものです。
たとえば、構造化されたデータによって容易になる。
- 複数のページ、ウェブサイト、概念にまたがるトピックのモデリングとクラスタリングが容易になり、新しいタイプの調査、比較、サービスが可能になります。
- アナリティクスデータを充実させ、コンテンツやパフォーマンスの分析をより深く、水平化して行えるようにする。
- 業務システムやウェブサイトのコンテンツを照会するための統一された(少なくとも接続された)言語と構文を作成すること。
- セマンティック検索:検索エンジン最適化に使用されるのと同じリッチなメタデータを使用して、内部検索システムを構築・管理すること。
私たちの研究結果は、必然的に検索エンジンの影響によって形作られますが、私たちは構造化データの他のタイプ、フォーマット、およびユースケースについても調査したいと考えています。
構造化データの種類とカバー率
構造化データには、多くの形式、標準、構文があります。私たちは、私たちのデータセット全体で、これらのうちもっとも一般的なものについてのデータを収集しました。
具体的には、以下のような構造化されたデータを特定し、抽出しています。
- Schema.org
- Dublin core
- ソーシャルネットワークで使用されるメタタグ:
- Microformats (とmicroformats2)
- RDFa, Microdata とJSON-LD
これらは、さまざまなユースケースとシナリオの広い概要を提供し、レガシーな標準と最新のアプローチの両方を含みます(たとえば、microformatsとJSON-LD)。
さまざまな構造化データ型における具体的な使用方法を探る前に、いくつかの注意点を簡単に調べておきましょう。
データの注意点
1. コンテンツマネジメントシステムの影響
評価したページの多くは、WordPress や Drupal などの コンテンツ管理システム(CMS)を使用しているWebサイトのものでした。これらのシステム、あるいはその機能を強化するテーマやプラグイン、モジュールは、分析対象の構造化データを含むHTMLマークアップを生成する役割を担っていることがよくあります。
つまり、私たちの調査結果は、もっとも普及しているCMSの動作や出力と一致するように偏ることを意味します。たとえば、Drupalを使用している多くのウェブサイトは、RDFaの形で構造化データを自動的に出力しますし、WordPress(かなりの割合のウェブサイトを動かす)はしばしばテンプレートコードにmicroformatsマークアップを含めます。これは、私たちの調査結果の形状に大きく寄与しています。
2. ホームページのみのデータの限界
残念ながら、このデータ収集方法の性質と規模から、分析対象はホームページのみ(つまり、評価した各ホスト名の root URL)に限定されます。
そのため、収集・分析できるデータの量が大幅に制限され、収集したデータの種類も偏ってしまうのは間違いありません。
多くのホームページは、より具体的なページへの入り口として機能しているため、今回の分析では、より深いページに存在するコンテンツの種類を過小評価していると考えるのが妥当であろう。その中には、記事、人、製品などの情報が含まれている可能性があります。
逆に、ホームページによくある情報やすべてのページに存在するサイト全体の情報、たとえばウェブページ、ウェブサイト、組織に関する情報などは、過剰にインデックスされる可能性が高いです。
3. データの重複
構造化データ形式の性質上、このような分析を大規模かつクリーンに行うことは困難です。多くの場合、構造化データは複数のフォーマットで実装され(重複することも多い)、構文とボキャブラリーの境界線があいまいになっています。
たとえば、FacebookやOpen Graphのメタデータは、技術的にはRDFaのサブセットと言えます。つまり、私たちの調査では、Facebookのメタタグを含むページをFacebookのカテゴリとRDFaのセクションで識別しています。私たちは、このようなタイプの重複やニュアンスを整理し、正規化し、意味をなすように最善を尽くしてきました。
4. モバイルメトリクス
今回のデータセット全体を通して、構造化データの採用と有無は、デスクトップとモバイルのデータセットでごくわずかに異なるだけです。そのため、ここでは簡潔にするため、主にモバイルデータセットに焦点を当てて説明します。
タイプ別使用状況
このセットの多くのページで、さまざまな種類の構造化データが、存在することがわかります。
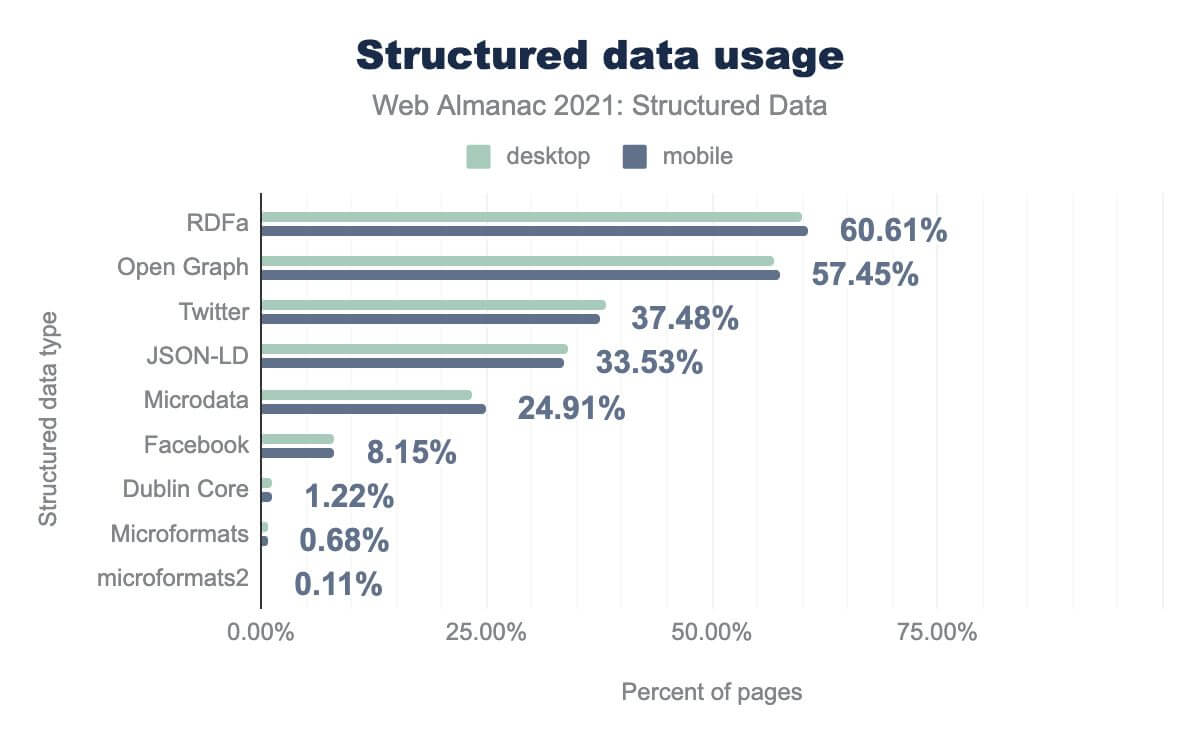
また、とくにRDFaとOpen Graphタグは非常に多く、それぞれ60.61%、57.45%のページに表示されていることが分かります。
一方、Microformatsやmicroformats2などのレガシーフォーマットは、ページの1%未満にしか表示されません。
シンタックスタイプ別カバレッジ
ある種の構造化データがいつ存在するかを特定するだけでなく、それが記述するデータの種類に関する情報を収集します。それぞれを分解し、各フォーマットと構文がどのように使用されているかを調べます。
RDFa
Resource Description Framework in Attributes(RDFa)は、2015年にW3Cが発表したリンクデータのマークアップのための技術である。マークアップに属性を追加することで、Webページ上の視覚情報を補強し、翻訳することができる。
たとえば、ウェブサイトの所有者は、ハイパーリンクに rel="license" 属性を追加して、それがライセンス情報ページへのリンクであることを明示的に記述できます。
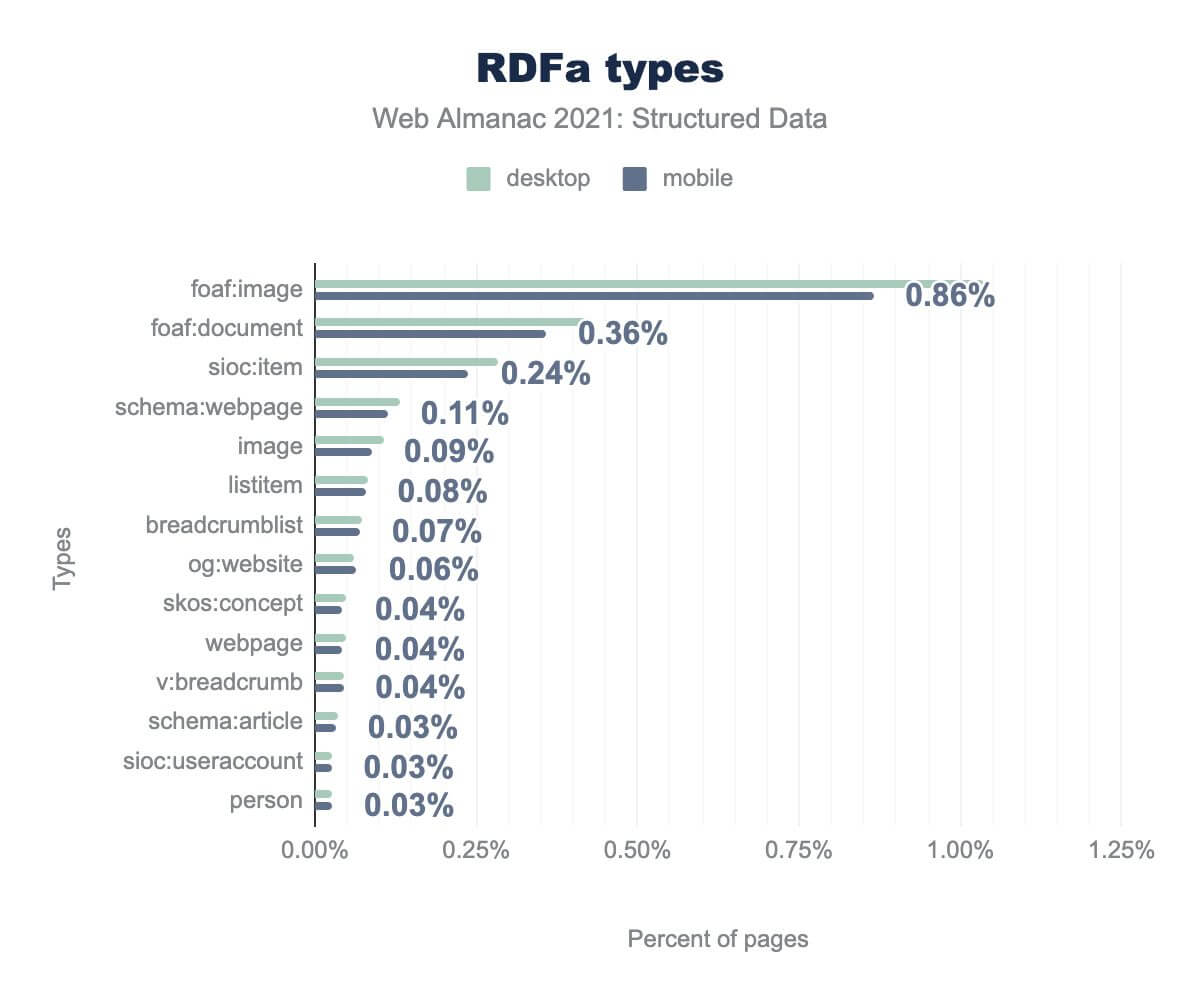
foaf:image は0.86%、 foaf:document では0.36%、 sioc:item では0.24%、 schema:webpage では0.11%、 image では0.9%、 listitem では0.08%、 breadcrumblist では007%、 og:website では0.06%、 skos:concept では0.04%、 webpage では0.04%、 v:breadcrumb では0.04%、 schema:article では0.03%、 sioc:useraccount では0.03%、そして person では0.03% であった。デスクトップでの使用率もほぼ同じです。RDFaのタイプを評価すると、foaf:image構文が他のタイプよりもはるかに多くのページに存在し、データセットの全ページの0.86%以上であることがわかります。これは小さな割合に見えるかもしれませんが、65,000ページを表し、発見されたRDFaマークアップ全体の60%以上に相当します。
この異常値を超えると、RDFaの使用はかなり減少し、断片的になるが、まだ興味深い発見がある。
FOAFについて
FOAF (または “Friend of a Friend”) は、2000年代初頭に作られた、人に関する用語のリンクデータ辞書である。人、グループ、文書の記述に使用できます。
FOAFはW3CのRDF構文を使っており、原文紹介では以下のように説明されています。
ある友人たちが興味を持つ事柄について書かれた、相互に関連するホームページのWebを考えてみよう。ウェブ上に現れるそれぞれの新しいホームページは、世界に新しい何かを伝え、事実やゴシップを提供し、ウェブを断絶された情報の断片の鉱山にしています。FOAFは、これらすべての情報を理解する方法を提供します。
Drupal CMSの古いバージョンでは、デフォルトで typeof="foaf:image" と foaf:document マークアップがHTMLに追加されているため、この結果では foaf マークアップが目立つと思われます。
その他の注目すべきRDFaの発見について
FOAFのプロパティだけでなく、他のさまざまな標準や構文がリストに表示されます。
注目すべきは、sioc:item(ページの0.24%)やsioc:useraccount(ページの0.03%)など、いくつかのsiocプロパティが確認できることです。SIOC は、メッセージボード、フォーラム、Wiki、ブログなどのオンラインコミュニティに関連する構造化データを記述するために設計された標準です。
また、SKOS (または “Simple Knowledge Organization System”) のプロパティである skos:concept が0.04% のページで見受けられました。SKOSもその1つで、分類や区分(タグやデータセットなど)を記述する方法を提供することを目的とした規格である。
Dublin Core
Dublin Core は、1995年にオハイオ州ダブリンで開催されたOCLC(Online Computer Library Center)とNCSA(National Center for Supercomputing Applications)のワークショップで考案されたリンクデータ標準と相互運用できるボキャブラリーである。
幅広いリソース(デジタルと物理の両方)を記述できるように設計されており、さまざまなビジネスシーンで利用することができる。2000年以降、RDFベースのボキャブラリーの中で非常に人気が高く、W3Cの採択を受けた。
2008年からはDublin Core Metadata Initiative(DCMI)によって管理され、他のリンクデータ語彙との高い相互運用性を維持している。通常、HTML文書内のメタタグの集合体として実装される。
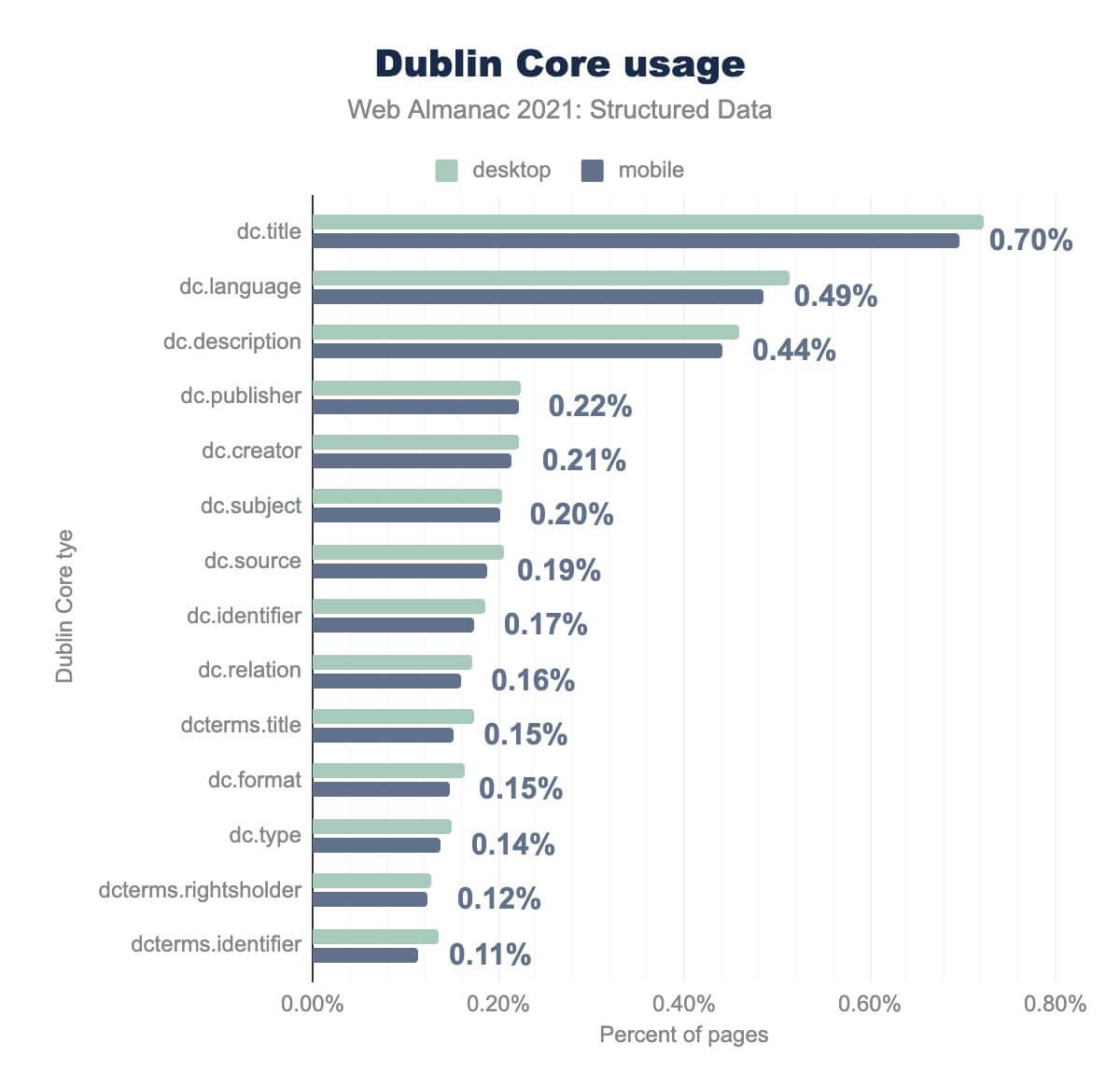
dc.title は0.70%、 dc.language では0.49%、 dc.description では0.44%、 dc.publisher では0.22%、 dc.creator では0.21%、 dc.subject では0.20%、 dc.source では19%、 dc.identifier が0.17%、 dc.relation が0.16%、 dcterms.title が0.15%、 dc.type が0.14%、 dcterms.rightsholder が0.12%、そして dcterms.identifier が0.11% となりました。デスクトップでの使用率もほぼ同じです。もっとも人気のある属性タイプはdc:title(0.70%のページ)であることは、驚くにはあたらない。しかし、dc:languageが0.49%の普及率で(description、subject、publisherなどの一般的な記述子より)次にあるのは興味深いことです。これは、Dublin Coreが多言語のメタデータ管理システムでよく使われていることを考えると、納得がいく。
また、異なる概念間の関係を表現することができる属性であるdc:relation(0.16%のページ)が比較的多く出現していることも興味深い。
SEOの文脈ではSchema.orgが優勢であると多くの人が思うかもしれませんが、DCの役割は、その概念の幅広い解釈とリンクされたオープンデータ運動に深く根ざしていることから、極めて重要であることに変わりはありません。
ソーシャルメタデータ
ソーシャル・ネットワークとプラットフォームは、構造化データの最大の発行者であり消費者でもあります。このセクションでは、構造化データフォーマットの役割、普及率、規模について説明します。
オープングラフ
オープングラフ・プロトコルは、オープンソースの規格で、もともとはFacebookが作成したものです。これは、コンテンツを共有するというコンテキストに特化した構造化データの一種で、Dublin CoreやMicroformatsなどの標準を緩やかにベースにしています。
これは、一連のメタタグとプロパティを記述したもので、プラットフォーム間で共有する際にコンテンツをどのように(再)表示するかを定義するために使用することができる。たとえば、投稿に「いいね!」を押したり、埋め込んだり、リンクを共有したりするときに使用します。
これらのタグは通常、HTML文書の <head> に実装され、ページの title, description, URL, featured image といった要素を定義します。
Open Graphプロトコルは、その後、Twitter、Skype、LinkedIn、Pinterest、Outlookなど、多くのプラットフォームやサービスで広く採用されるようになりました。プラットフォームが共有/埋め込みコンテンツの表示方法について独自の基準を持っていない場合(時には持っている場合でも)、Open Graphタグはデフォルトの動作を定義するためによく使用されます。
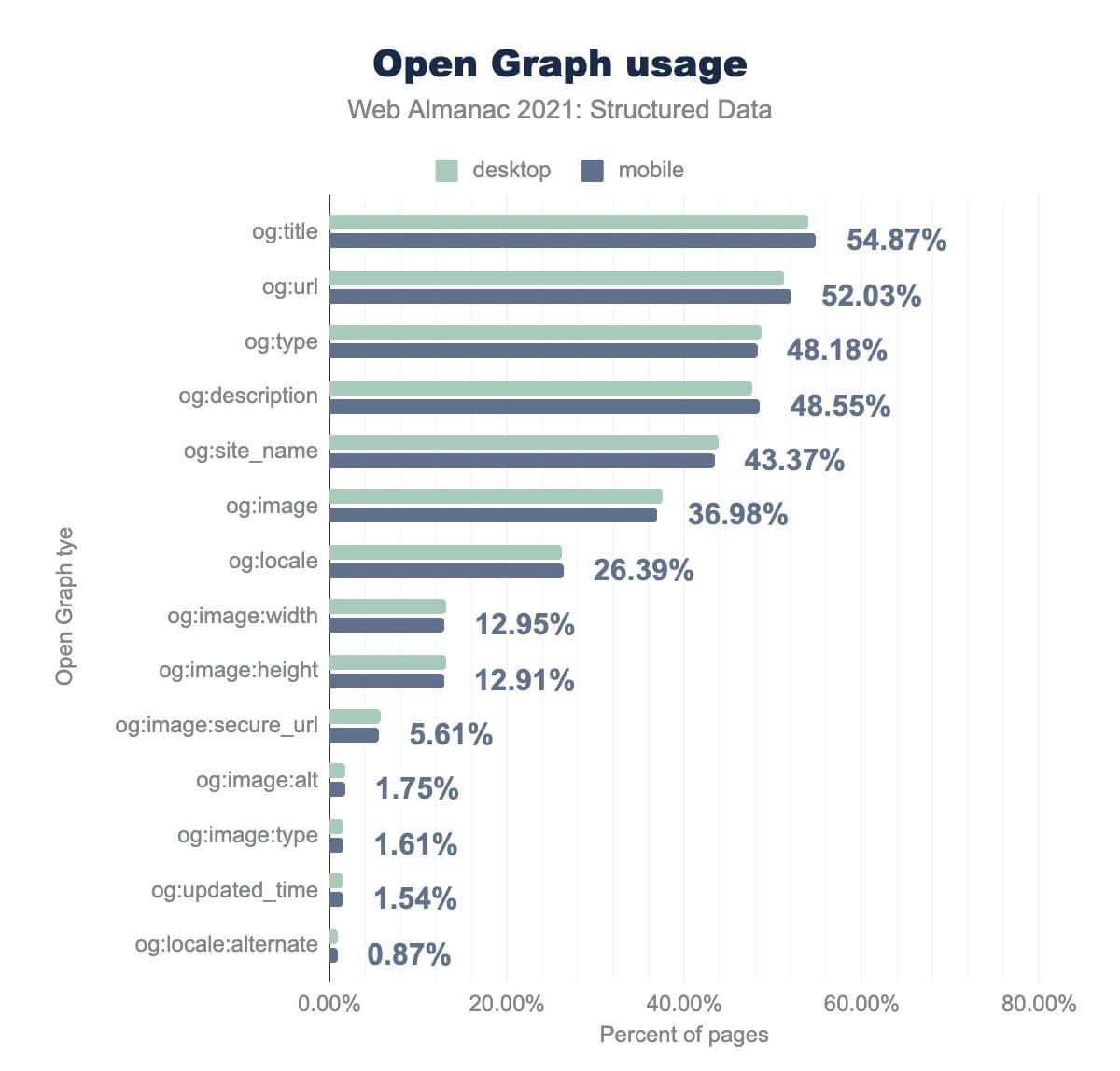
title が54.87%、 og:url が52.03%、 og:type が48.18%、 og:description が48.55%、 og:site_name が43.37%、 og:image が36.98%、 og:locale が26.39%、 og:image:width が12.40%、og:security が12.40%、go:text が12.40%、 gogo が3.40%、ogo:text が3.40%です。 95%、 og:image:height が12.91%、 og:image:secure_url がWeb上でのOpen Graphタグの利用状況を示す棒グラフ。データに含まれるすべてのモバイルページのうち og:title が54.87%、 og:url が52.03%、 og:type が48.18%、 og:description が48.55%、 og:site_name が43.37%、 og:image が36.98%、 og:locale が26.39%、 og:image:width が12.95%、 og:image:height が12.91%、 og:image:secure_url が5.61%、 og:image:alt が1.75%、 og:image:type が1.61%、 og:updated_time が1.54%、そして og:locale:alternate が0.87% であります。デスクトップでの使用率もほぼ同じです。5.61%、 og:image:alt が1.75%、 og:image:type が1.61%、 og:updated_time が1.54%、そして og:locale:alternate が0.87% であります。デスクトップでの使用率もほぼ同じです。もっとも一般的なOpen Graphタグはog:titleであり、54.87%のページで見受けられる。これは、どのような種類のものが表現されているか(例: og:type ページの48.18%に掲載)、どのように表現されるべきか(例: og:descriptionページの48.55%に掲載)を記述する関連属性のセットに密接に追随しています。
これらのタグは、サイト上のすべてのページの <head> で使用される「定型」タグの一部として一緒に使用されることが多いので、この狭い分布は予想されることです。
やや少ないのは og:locale(26.39%のページ)で、これはページのコンテンツの言語を定義するために使用されます。
さらに少ないのは、og:imageタグに関するより具体的なメタデータで、og:image:width(12.95%のページ)、og:image:height(12.91%のページ)、 og:image:secure_url(5.61% のページ)と og:image:alt(1.75% のページ)の形式です。 HTTPSの採用がますます一般的になっている現在、og:image:secure_url(og:imageのhttpsバージョンを識別するためのもの)はほとんど冗長になっていることは注目に値します。
これらの例を超えると使用頻度は急速に低下し、(多くの場合、不正、非推奨、または誤った)タグのロングテールになってしまいます。
TwitterはOpen Graphタグをフォールバックやデフォルトとして使用していますが、このプラットフォームは独自の構造化データをサポートしています。TwitterでURLが共有されたときに、どのようにページを表示するかを定義するために、特定のメタタグ(すべて接頭辞がtwitter:)を使用できます。
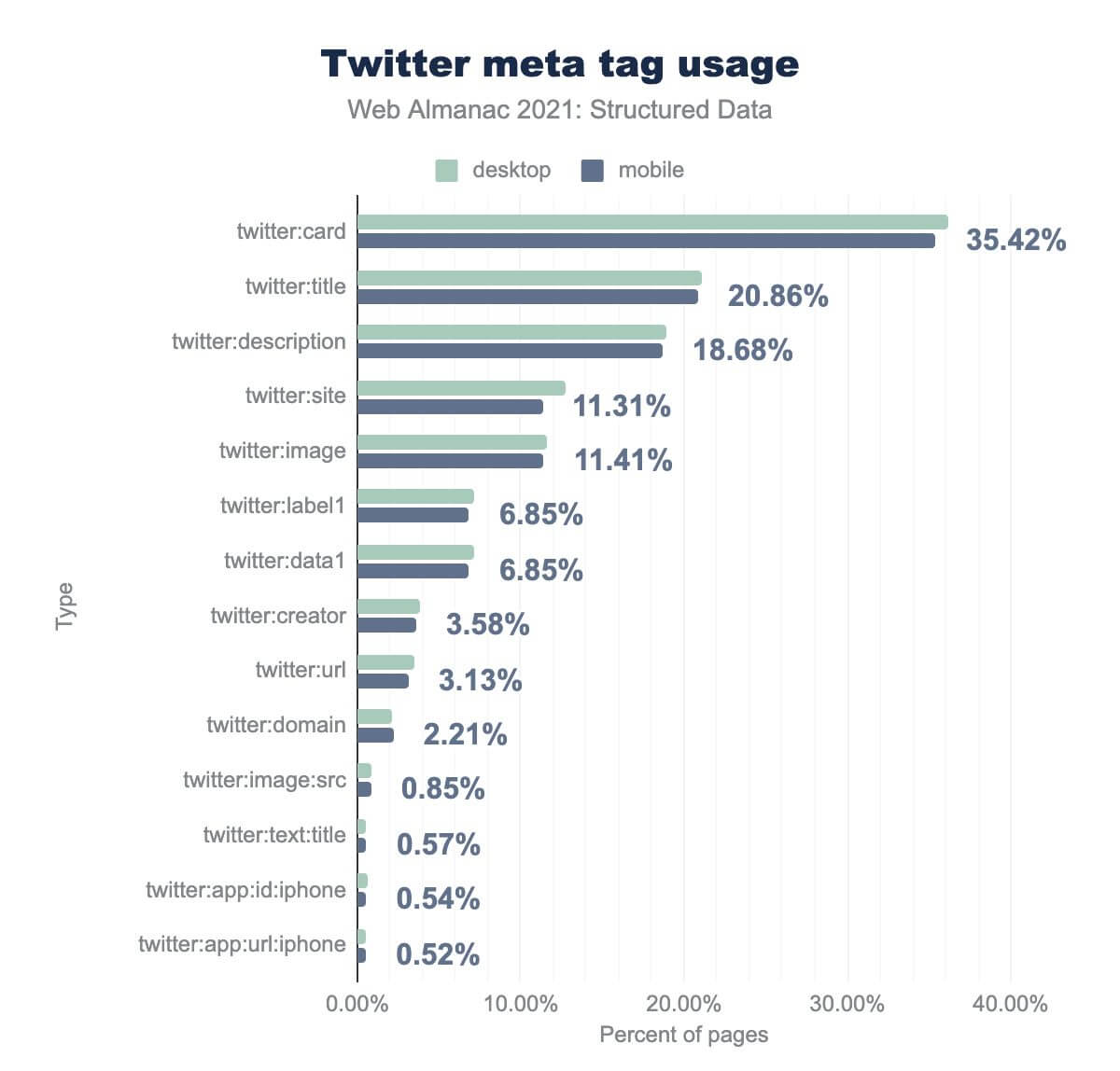
twitter:card が35.42%、twitter:title が20.86%、twitter:description が18.68%、twitter:site が11.31%、twitter:image が11.41%、twitter:label1 が6.85%, twitter:data1 が6.85%、twitter:creator が3.58%、twitter:url が3.13%、twitter:domainが2.21%、twitter:image:src が0.58%, twitter:text:title が0.57%、 twitter:app:id:phone が0.54%、twitter:app:url:iphone が0.52% であった。デスクトップでの使用率もほぼ同じです。もっとも一般的なTwitterのメタタグはtwitter:cardで、全ページの35.42%に見られました。このタグは、プラットフォームで共有される際のページの表示方法を定義するために使用できます(例:summary、メディアオブジェクトに関する追加データと組み合わせた場合のplayerなど)。
この異常値を超えると、採用率は急降下する。次に多いタグはtwitter:titleとtwitter:description(どちらも共有URLの表示方法を定義するために使用)で、それぞれ全ページの20.86%と18.68%に表示されます。
これらのタグや、twitter:imageタグ(ページの11.41%)とtwitter:urlタグ(ページの3.13%)の普及が進まない理由は、Twitterが定義されていない場合、同等のOpen Graphタグ(og:title, og:description とog:image)に戻るためであると理解できます。
また、注目すべきは
- 当該ウェブサイトに関連するTwitterアカウントを定義する
twitter:siteタグ(11.31%のページ)です。 twitter:creatorタグ(3.58%)は、ウェブページのコンテンツの作者のTwitterアカウントを定義しています。twitter:label1タグとtwitter:data1タグ(ともに6.85%のページに掲載)は、ウェブページに関するカスタムデータと属性を定義するために使用できます。追加のラベル/データのペア(例:twitter:label2とtwitter:data2)も、かなりの数(0.5%)のページに存在しています。
これらの例を超えると使用頻度は急速に低下し、(多くの場合、不正、非推奨、または誤った)タグのロングテールになってしまいます。
Facebookは、Open Graphタグに加えて、Webページをプラットフォーム上の特定のブランド、プロパティ、人物に関連付けるための追加のメタデータ(metaタグ、接頭辞はfb:)をサポートしています。
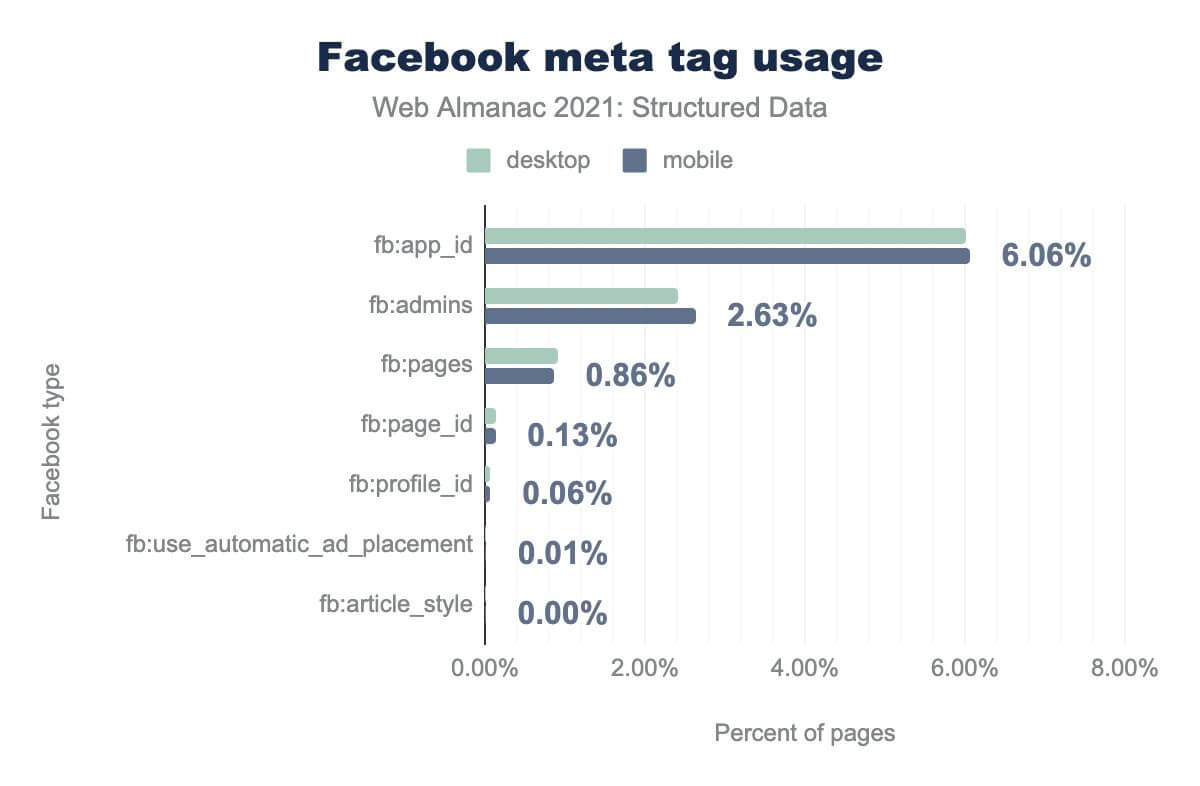
fb:app_idは6.06%、fb:adminsでは2.63%、fb:pagesは0.86%、fb:page_idでは0.13%、fb:profile_idは0.06%、fb:use_auto_ad_placementでは0.01%、そして fb:article_style は0.01% 以下であることがわかります。デスクトップでの使用も同様です。検出されたFacebookタグのうち、有意に採用されたタグは3つだけです。
これらは fb:app_id, fb:admins, fb:pages で、それぞれ6.06%, 2.63%, 0.86% のページで確認されました。
これらのタグは、ウェブページとFacebookページ/ブランドを明示的に関連付けるため、またはこれらのプロファイルを管理するユーザー(または複数のユーザー)に権限を付与するために使用されます。
また、Facebook社がどの程度サポートしているかは不明です。Facebookはここ数年で大きく変化しており、技術文書もあまり整備されていません。しかし多くのコンテンツ管理システム、テンプレート、ベストプラクティスガイド、そしてFacebookのデバッグツールの中には、まだこれらが含まれ、参照されているものがあります。
Microformatsとmicroformats2
Microformats(一般にμFと略される)は、HTMLにセマンティクスと構造化データを埋め込むためのメタデータのオープンデータ規格です。
これらは、見出しや段落などの通常のHTML要素の背後にある意味を記述する、定義されたクラスのセットで構成されています。
この構造化データのフォーマットは、広く採用されている標準規格(セマンティック(X)HTML)を再利用してセマンティクスを伝えることを指針としています。公式ドキュメントは、Microformatsを「人間が第一、機械が第二のために設計された」と説明し、「既存の広く採用されている標準に基づいて作られた、シンプルでオープンなデータ形式の集合」であるとしています。
Microformatsは2つのバージョンで提供されています。Microformats v1とMicroformats v2(microformats2)です。2014年3月に導入された後者は、v1を置き換えて優先し、microdataとRDFaの両方の構文から学んだいくつかの重要な教訓を活用しています。
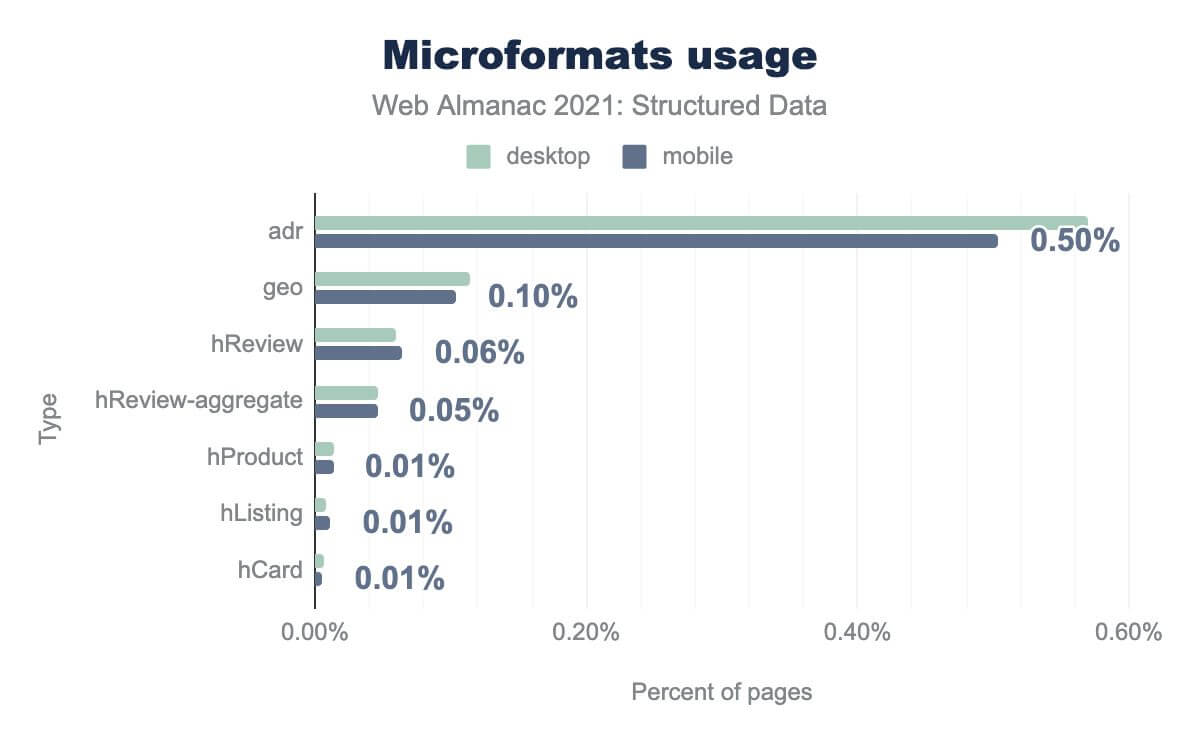
adr は0.50%、 geo で0.10%、 hReview で0.06%、 hReview-aggregate で0.05%、 hProduct で0.01%、 hListing で0.01%、 hCard では0.01%です。デスクトップでの使用率もほぼ同じです。歴史的に、またその性質上(HTMLの拡張として)、Microformatsは企業や組織のプロパティを記述するために、ウェブサイト開発者によって多用されてきました。とくにローカルビジネスを促進するページ。これは、adrプロパティ(ページの0.50%)、レビュー(hReview、ページの0.06%)、その他のローカルビジネスとその製品/サービスを特徴付けるための情報が目立つことを説明するのに大いに役立ちます。
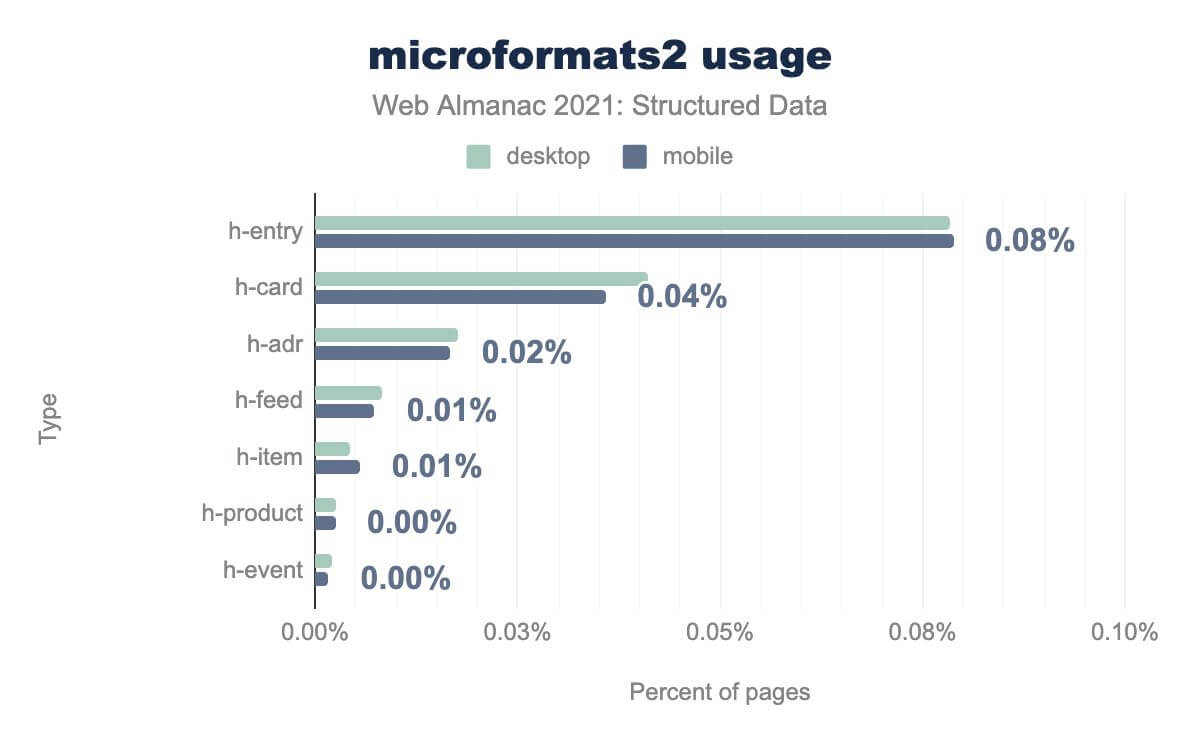
h-entryは0.08% h-card では0.04% h-adr では0.02% h-feed では0.01% h-item では0.01% h-product では0.01% 未満、 h-event では0.01% 未満となっています。デスクトップでの使用率もほぼ同じです。レガシーなマイクロフォーマットとよりモダンなバージョンの違いは大きく、マークアップの使用における行動や嗜好の変化に関する興味深い洞察が得られます。
adr クラスが古典的なmicroformatsのデータセットを支配していたところ、同等の h-adr プロパティは0.02% のページ上にしか存在しません。この結果は、代わりに h-entry プロパティ(ページの0.08% にあり、ブログ記事と同様のコンテンツユニットを記述)と h-card プロパティ(ページの0.04% にあり、組織や個人の 名刺 を記述)によって支配されています。
この差の原因として考えられるのは、次の3点である。
- 一般的なクラス名(
adrなど)のデータは、私たちのmicroformats v1データでは、ほぼ確実に過大評価されています。これらの値が、構造化データとより一般的な理由(たとえば、CSSルールを伴うHTMLクラス属性値として)で使われる場合を見分けるのは困難です。 - 一般的なマイクロフォーマットの使用は(種類を問わず)大幅に減少し、他のフォーマットに置き換えられています。
- 多くのウェブサイトやテーマでは、一般的なデザイン要素やレイアウトに
h-entry(時にはh-card) マークアップをまだ含んでいます。たとえば、多くのWordPressテーマでは、メインコンテンツコンテナーにh-entryクラスが出力され続けています。
Microdata
microformatsやRDFaと同様に、microdataは、HTML要素に属性を追加することを基本としています。microformatsとは異なりますが、RDFaと同様に、定義された意味の集合に縛られることはありません。この規格は拡張可能で、作者はどのボキャブラリーのデータを記述するかを宣言することができる。もっとも一般的なのはschema.orgである。
microdataの限界の1つは、エンティティ間の抽象的で複雑な関係を記述するのが困難なことで、その関係がページのHTML構造に明示的に反映されていない場合です。
たとえば、ある組織の営業時間を記述する場合、その情報が文書内で同時に、または論理的に構成されていないと難しいかもしれません。なお、この問題を解決するための標準や方法論(たとえば、インラインの <meta> タグやプロパティを含めるなど)はありますが、広く採用されているわけではありません。
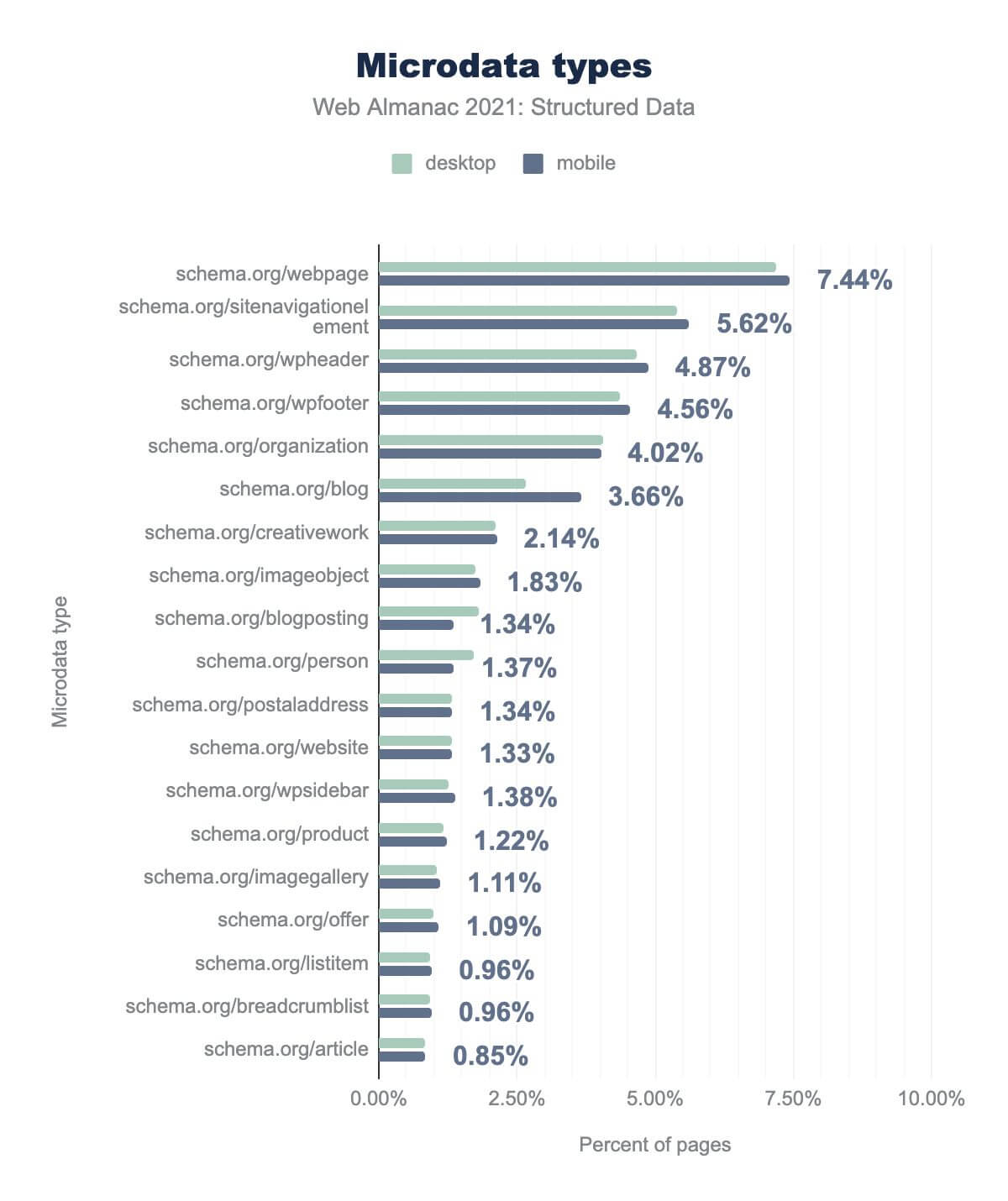
schema.org/ を削除して正規化)のうち、 webpage は7.44%、 sitenavigationelement で5.62%、 wpheader で4.87%、 wpfooter で4.56%、 organization で4.02%、 blog で3.66%、 creativework で2.14%、 imageobject で1.83%、 blogposting で1.34%、 person では1.37%、 postaladdress で1.34%、 website で1.33%、 wpsidebar で1.38%、 product で1.22%、 imagegallery が1.11%、 offer が1.09%、 listitem が0.96%、 breadcrumblist が0.96%、そして article が0.85% です。デスクトップでの使用率もほぼ同じです。分析したページでもっとも一般的なmicrodataのタイプは、Webページそのものを記述するもので、webpage(7.44%のページ)、sitenavigationelement(5.62%のページ)、wpheader(4.87% of pages)とwpfooter(4.56% of pages)などのプロパティが利用されました。
なぜこのような構造的な記述子がコンテンツ記述子(personやproductなど)よりも目立つのかは簡単に推測できます。マイクロデータの作成と維持には、コンテンツ制作者がコンテンツに特定のコードを追加する必要がありますが、それはコンテンツレベルよりもテンプレートレベルで行う方が、簡単なことが多いのです。
マイクロデータの強みの1つは、HTMLマークアップとの明確な関係(およびその中でのオーサリング)ですが、そのため、マイクロデータを使用するための技術的な知識と能力を持つコンテンツ制作者へのアプローチは限られています。
とはいえ、マイクロデータの種類は幅広く、さまざまなものが採用されていることがわかります。特筆すべきは
Organization(4.02%)は、通常、ウェブサイトを公開する会社、製品の製造会社、著者の雇用主、または同様のものを表します。CreativeWork(2.14%)は、すべての文章と画像コンテンツ(例:ブログ記事、画像、ビデオ、音楽、アート)を記述するもっとも一般的な親タイプです。BlogPosting(1.34%)、これは個々のブログ投稿を記述します(一般に、著者としてPersonも特定されます)。Person(1.37%)これは、コンテンツの作者やページに関係する人(例:ウェブサイトの発行者、出版組織のオーナー、商品を販売する個人など)を表すのによく使われます。Product(1.22%) とOffer(1.09%) は、一緒に使用すると、購入可能な製品を説明します(通常、価格、レビュー、入手可能性を説明する追加のプロパティが付きます)。
JSON-LD
microdataやmicroformatsとは異なり、JSON-LD はHTMLマークアップにプロパティやクラスを追加することによって実装されるものではありません。その代わり、機械可読のコードは、JavaScript Object Notationの1つまたは複数の独立した塊としてページに追加されます。このコードには、ページ上の実体とその関係の説明が含まれています。
この実装は、ページのHTML構造と直接結びついていないため、複雑な関係や抽象的な関係を記述したり、人間が読めるページの内容では容易に得られない情報を表現することがはるかに容易になります。
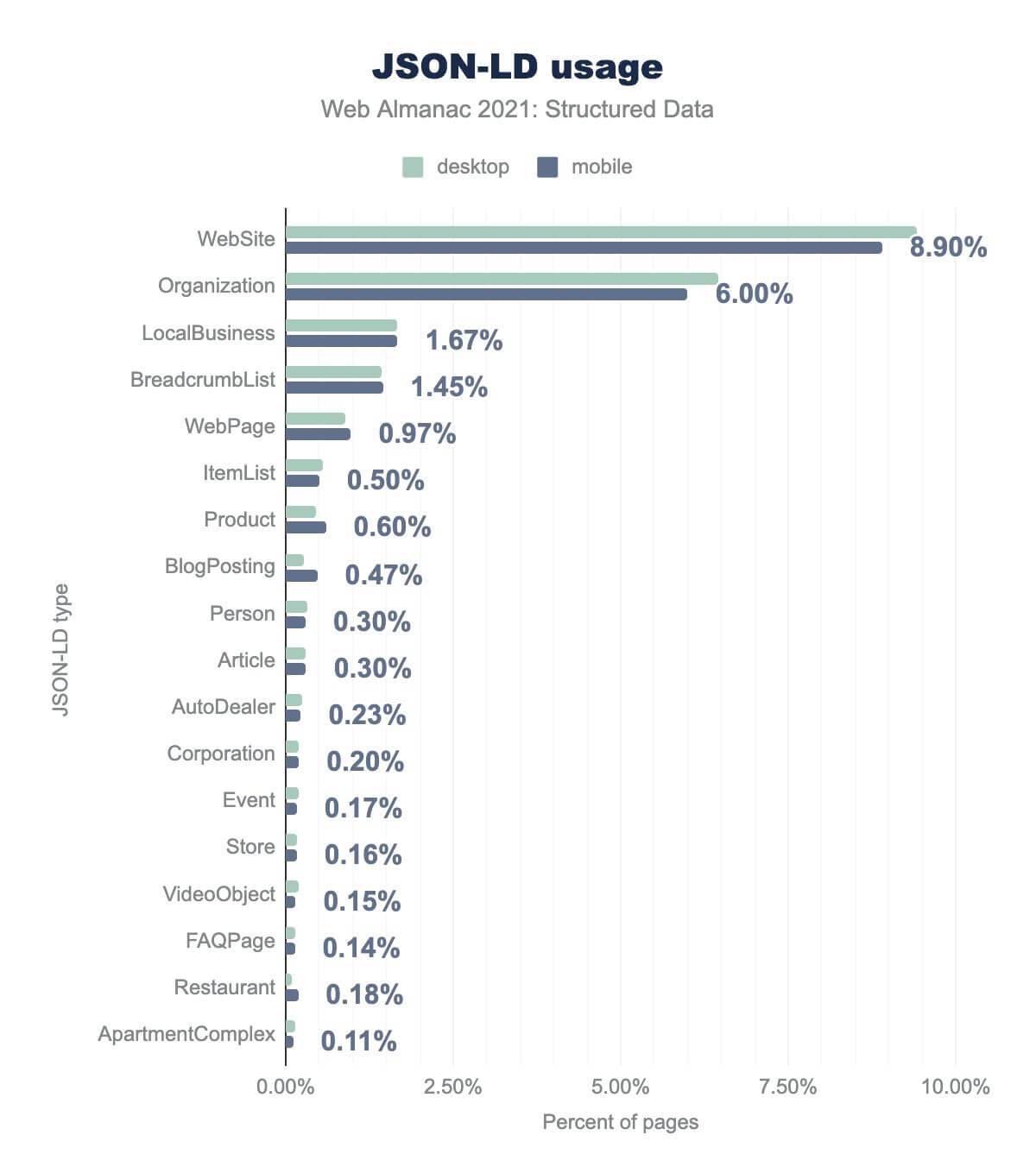
Website は8.90%、Organization で6.00%、LocalBusiness で1.67%、BreadcrumbList で1.45%、WebPage で0.97%、ItemList で0.50%、Product で0.60%、BlogPosting で0.46%、Person で0.40%。 30%, Article で0.30%, AutoDealer で0.23%, Corporation で0.20%, Event で0.17%, Store で0.16%, VideoObject で0.15%, FAQPage で0.14%, Restaurant で0.18% そして ApartmentComplex で0.11% であった。デスクトップでの使用率もほぼ同じです。予想されるように、今回の結果はmicrodataの利用を評価した結果と似ています。どちらのアプローチもschema.orgの使用に大きく偏っているため、この結果は拡大解釈されるでしょう。しかし、いくつかの興味深い違いがあります。
JSON-LD形式は、サイトオーナーがHTMLマークアップとは別にコンテンツを記述できるため、ページのコンテンツへそれほど厳密に縛られない、より抽象的で複雑な関係を表現することが容易になる可能性があるのです。
このことは、今回の調査結果にも反映されており、より具体的で構造化された記述子がマイクロデータよりも一般的であることがわかる。たとえば
BreadcrumbList(ページの1.45%) は、ウェブサイトにおけるウェブページの階層的な位置を説明します(各親ページについても説明します)。ItemList(ページの0.5%): レシピ の ステップ や カテゴリー の 製品 など、一連のエンティティを記述します。
これらの例以外では、マイクロデータの時と同じようなパターンが引き続き見られます(規模はかなり小さいですが)。Webサイト、地元企業、組織、Webページの構造に関する記述が、広範な採用の大部分を占めています。
JSON-LDの構造および関係
JSON-LDの主な利点の1つは、他のフォーマットよりもエンティティ間の関係をより簡単に記述できることである。
たとえば、イベントには、主催する法人があり、特定の場所で開催され、オファーの一部としてチケットが、販売されることがあります。そのイベントを説明するブログ記事には作成者があり、といった具合に。このような関係の記述は、他の構文に比べてJSON-LDの方がはるかに簡単で、実体に関する豊かな物語を伝えるのに役立ちます。
しかし、こうした関係は往々にして深く、複雑に絡み合っていくものです。したがって、この分析では、エンティティ間のもっとも一般的なタイプの関係のみを調べ、ツリーや関係構造全体を評価することはしません。
以下は、すべての構造/関係値において、タイプ間のもっとも一般的な接続を、その頻度に基づいて示しています。なお、これらの構造や価値は、より大きな関係性の連鎖の一部であるため、時には重なり合うこともあります。
| 関係性 | デスクトップページの% | モバイルページの% |
|---|---|---|
WebSite > potentialAction > SearchAction |
6.44% | 6.15% |
| 5.06% | 4.85% | |
@graph > WebSite |
4.89% | 4.69% |
WebPage > isPartOf > WebSite |
4.02% | 3.81% |
@graph > WebPage |
4.01% | 3.79% |
BreadcrumbList > itemListElement > ListItem |
3.93% | 3.78% |
Organization > logo > ImageObject |
2.85% | 3.03% |
@graph > BreadcrumbList |
3.18% | 2.99% |
WebPage > potentialAction > ReadAction |
2.92% | 2.71% |
WebPage > breadcrumb > BreadcrumbList |
2.60% | 2.44% |
WebSite |
2.49% | 2.30% |
@graph > Organization |
2.26% | 2.13% |
WebSite > publisher > Organization |
2.22% | 2.09% |
Product > offers > Offer |
1.47% | 1.89% |
Product |
1.41% | 1.73% |
@graph > ImageObject |
1.80% | 1.71% |
ItemList > itemListElement > ListItem |
1.71% | 1.69% |
@graph > SiteNavigationElement |
1.70% | 1.66% |
WebPage > primaryImageOfPage > ImageObject |
1.67% | 1.59% |
もっとも多い構造は、website、potentialAction、SearchActionスキーマの関係です(構造の6.15%を占めます)。この関係により、Googleの検索結果にサイトリンク検索ボックスを利用できます。
おそらくもっとも興味深いのは、次に多い構造(関係の4.85%)が、関係を定義していないことである。これらのページは、もっとも単純なタイプの構造化データのみを出力し、個々の孤立した実体とそのプロパティを定義する。
次に多い構造(リレーションシップの4.69%)は、@graphプロパティを導入しています(Websiteの記述と合わせて)。@graph プロパティはそれ自体ではエンティティでないですが、JSON-LDではエンティティ間の関係を含み、グループ化するために使用できます。
さらに関係を探っていくと、WebPage > isPartOf > WebSite(関係の3.81%)、Organization > logo > ImageObject(関係の3.03%)、WebSite > publisher > Organization(関係の2.09%)など、コンテンツと組織の関係についてさまざまな記述が見受けられるようになりました。
また、パンくずナビに関連する構造もたくさん見ることができます。
BreadcrumbList > itemListElement > ListItem(3.78%の関係性)@graph > BreadcrumbList(2.99%の関係)ItemList > itemListElement > ListItem(1.69%の関係性)
これらのもっとも一般的な構造以外にも、ApartmentComplex > amenityFeature > LocationFeatureSpecification (0.1%の関係性)や AutoDealer > department > AutoRepair (0.04%の関係性)、MusicEvent > performer > PerformingGroup (0.01%の関係性)など、あらゆるエンティティ、コンテンツタイプ、概念を説明する非常に長いテールの関係を見てとることができます。
このような構造や関係は、ウェブサイトのホームページの分析に限られているため、今回のデータセットが示すよりもはるかに一般的である可能性があることを再度確認しておきます。たとえば、何千もの集合住宅を個別に掲載しているウェブサイトが、内側のページでそれを行っている場合、このデータには反映されないということです。

WebPage は最大の “From” アイテムで、複数の “Relationship” タイプと “To” 結果に分岐しています (たとえば、WebPage -> PotentialAction -> SearchAction)。続いて、WebSite、Organization、Product、BreadCrumblist、BlogPostingと続き、徐々に他の項目が使用されるようになります。真ん中の”Relationships”の列では、PotentialActionがもっともよく使われ、次に ItemListElement, IsPartOf, Publisher, image と続き、その後、同様のロングテールでどんどん使用率が下がっていきます。”To”列では、ImageObjectがもっとも使用されており、次にOrganization、SearchAction、ListItem、WebSite、WebPageと続き、さらに長い尾を引いて使用率が減少しています。このグラフから感じられるのは、3つのカラムの間に多くが混同して使用しており、さまざまな関係があるということです。モバイルページにおけるJSON-LDエンティティ間の相関を示し、フローとして表現することで、エンティティやリレーションシップを視覚的に結びつける図です。各クラスはクラスター内の一意な値を表し、高さはその頻度に比例する。
このグラフでは、分析対象は頻度の高い上位200チェーンに限定しています。
また、このグラフから、一般出版からeコマース、地域ビジネス、イベント、自動車、音楽など、これらのグラフの背景にある分野を概観できます。
関係性の深さ
さらに、モバイルとデスクトップのデータセットにおいて、エンティティ間のもっとも深く複雑な関係を計算しました。
関係が深ければ深いほど、エンティティ(およびそれに関連する他のエンティティ)のより豊かで包括的な記述に等しくなる傾向があります。
深い関係性は
- デスクトップでは、18のネストした接続の深さ。
- モバイルの場合、12個のネスト接続の深さ。
このような構造は、規模が大きくなると記述や維持が困難になるため、手作りのマークアップではなく、プログラムによる出力生成の可能性を示唆するものであると考える価値があります。
sameAsの使用
構造化データのもっとも強力な使用例の1つは、ある実体が他の実体とsameAsであることを宣言することである。あるものを包括的に理解するためには、多くの場合、複数の場所や形式に存在する情報を消費する必要があります。それぞれのインスタンスが他のインスタンスと相互参照できる方法があれば、「点と点を結ぶ」ことが容易になり、その実体をより豊かに理解できます。
このように、sameAsは非常に強力なツールであるため、ここではもっとも一般的なsameAsの使用方法と関係性について、時間をかけて調べてみました。
sameAs 宣言の使用状況を示す棒グラフです。データ中の全モバイルのうち facebook.com が4.26%、instagram.com が2.74%、twitter.com が2.46%、youtube.com が1.78%、linkedin.com が1.04%、pinterest.com が0.60%、google.com が0.51%、yelp.com、wikidata.org が0.12%、wikipedia.org が0.11%、 tumblr.com が0.08% 、 uptodown.io が0.10%、 vk.com が0.08%、 soundcloud.com が0.04%、 vimeo.com が0.03%、 pinterest.co.uk が0.03%、 tripadvisor.com が0.03%、 t.me が0.03%、そして flickr.com が0.02% であったと報告しています。デスクトップでの使用率もほぼ同じです。sameAsプロパティは全JSON-LDマークアップの1.60%を占め、ページの13.03%に存在しています。
もっとも一般的な sameAs プロパティ(URL からホスト名への正規化)の値は、ソーシャル メディア プラットフォーム(例:facebook.com、instagram.com)と公式ソース(例:wikipedia.org、yelp.com)で、前者の合計が使用率の約75% を占めていることがわかります。
このプロパティは、主にウェブサイトや企業のソーシャルメディアアカウントを特定するために使用されていることは明らかです。おそらく、Googleが検索結果のナレッジパネルを管理するための入力として、このデータに歴史的に依存していることが動機となっているのでしょう。この要件が2019年に非推奨となったことを考えると、このデータセットが今後、徐々に変化していくことが予想されるかもしれません。
結論
構造化データは、ウェブ上で広く、そして多様に使用されています。その一部は間違いなく陳腐化していますが(時代遅れのフォーマットを使用したレガシーなサイトやページ)、新しい標準や新興の標準も強力に採用されています。
schema.org(とくにJSON-LD経由)のような最新の標準の採用は、ページやコンテンツに関するデータの提供に対する検索エンジンのサポート(および報酬)を利用したい組織や個人によって動機づけられているように見受けられるという逸話があります。しかし、これ以外にも、他の理由で構造化データを使ってページを充実させている人たちの豊かな風景があるのです。他のシステムと統合し、コンテンツをよりよく理解するため、あるいは他の人が自分自身のストーリーを語り、独自の製品を構築するのを容易にするためウェブサイトやコンテンツを記述するのです。
深く結びついた構造化データからなるウェブが、より統合された世界を動かすというのは、長い間SF的な夢だった。しかし、おそらく、もうそれほど長くはないでしょう。これらの規格が進化し、その普及が進むにつれ、私たちはエキサイティングな未来への道を切り開くことになります。
今後の展開
将来的には、ここで始めた分析を継続し、構造化データ利用の時間的な変遷をマップ化できるようにしたいと考えています。
さらなる探求を期待しています。

